大模型 RAG 实践
RAG(Retrieval-Augmented Generation,检索增强生成)是一种 将「检索」+「大模型生成」结合起来的 AI 技术框架。它可以让大模型在回答问题时,不只依靠自身固有的参数知识,还能实时检索外部资料(如文档、数据库、网页、企业知识库等),再基于这些资料进行回答。
RAG = 检索(Retrieve) + 生成(Generate)
一、为什么需要 RAG?
因为大模型本身存在:
- 知识有截止日期(知识过时)
- 容易幻觉(胡编乱造)
- 无法直接访问你的私有数据(代码、文档、业务资料)
RAG 通过加入“外部检索”,解决了这些问题,让模型回答:
- 更准确、可控
- 可访问企业内部知识
- 实时可更新,不需要重新训练模型
二、RAG 的工作流程
- 构建知识库:文档,网页,pdf
- 转成向量,有专门的 embedding 模型
- 存入向量数据库
- 用户提问
- 检索阶段
- 把用户提问向量化
- 在之前存的向量数据库中找最相似(余弦相似度)的最相关几个片段(top-k)
- 生成阶段
- 将检索到的资料作为 context 提供给 LLM
- LLM 根据 context 生成回答
可能会有一个如下的架构设计:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| [文档/代码/知识库]
│
预处理切片
│
文本向量化(Embedding)
│
向量数据库(Qdrant / Milvus)
│
用户问题 → embedding → 相似度检索
│
[检索到的内容 + 问题]
│
大模型生成(LLM)
│
返回答案
|
三、RAG 的核心优势?
- 减少幻觉:因为模型必须基于检索结果回答
- 无需训练:不用微调模型,只需更新知识库
- 成本低:embedding 便宜得多(相比 finetune)
- 数据可控:企业内部数据不需要上传给模型训练
- 可实时更新:新增一份文档 → 只需重新 embedding 即可
- 可解释性强:可以展示来源文档
四、来一个实践
下面这张图是自己做的一个简单的 RAG 实践 demo,逐步展开一下实现方式。
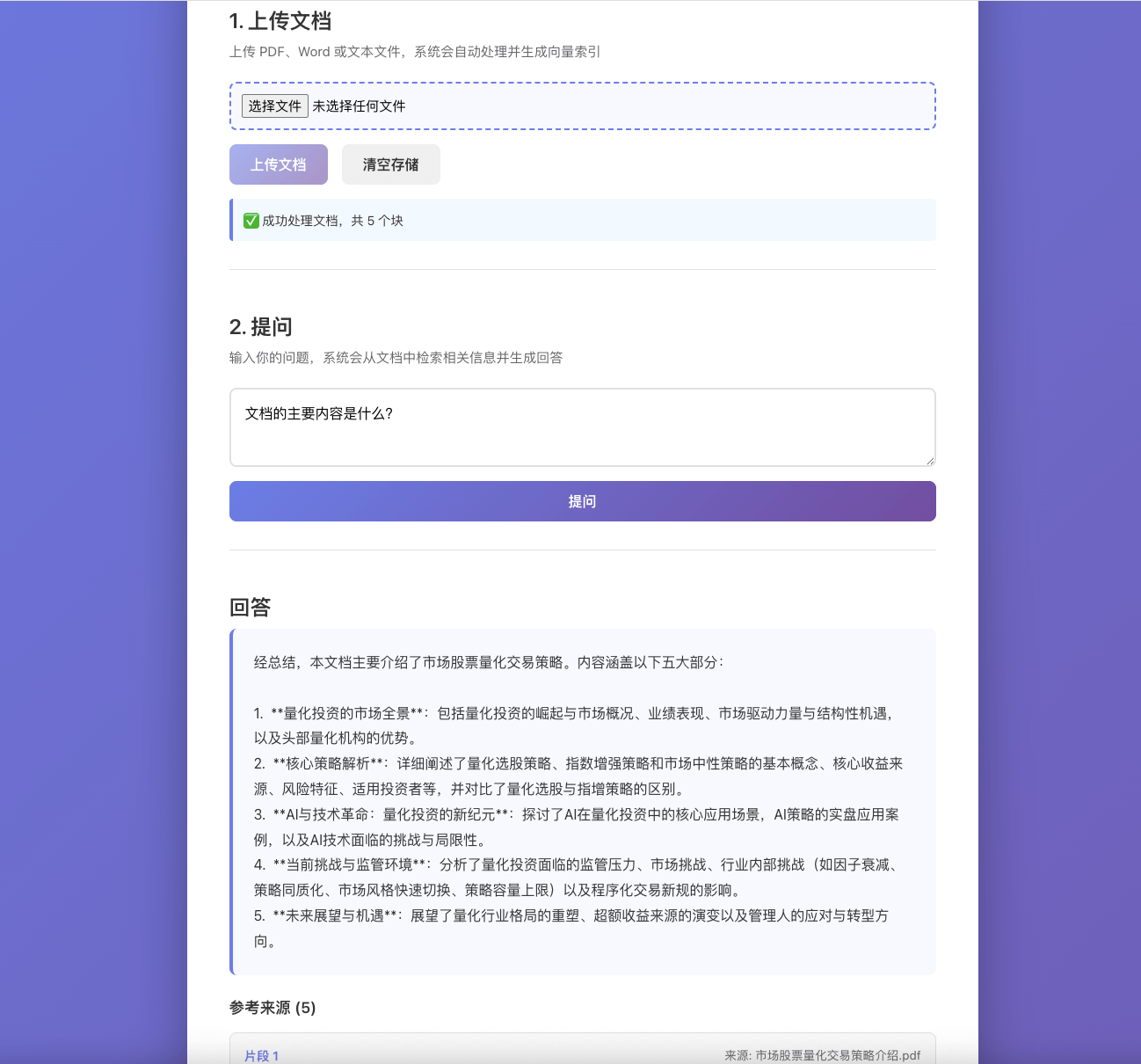
1. 处理文本
首先需要对知识库进行处理,来源后缀可能是: txt、pdf、docx、md 等。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
export async function processPDF(file: File): Promise<string> {
const arrayBuffer = await file.arrayBuffer();
const buffer = Buffer.from(arrayBuffer);
const data = await pdfParse(buffer);
return data.text;
}
export async function processWord(file: File): Promise<string> {
const arrayBuffer = await file.arrayBuffer();
const buffer = Buffer.from(arrayBuffer);
const result = await mammoth.extractRawText({ buffer });
return result.value;
}
export async function processText(file: File): Promise<string> {
return await file.text();
}
|
2. 文本切片
需要文本切片的原因是:
- 文本过长,Embedding 模型无法处理
- 提高检索精度,切片后,检索能定位到更细粒度片段
- 控制上下文窗口大小,大模型的上下文窗口有限。切片后,可以只将最相关的几个片段(如 topK=5)放入上下文,避免超出限制
- 提升计算效率,批量生成 embeddings,可以批量处理多个切片
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
export function chunkText(
text: string,
chunkSize: number = 1000,
overlap: number = 200
): string[] {
const chunks: string[] = [];
let start = 0;
while (start < text.length) {
const end = Math.min(start + chunkSize, text.length);
let chunk = text.slice(start, end);
if (end < text.length) {
const lastPeriod = chunk.lastIndexOf('.');
const lastNewline = chunk.lastIndexOf('\n');
const splitPoint = Math.max(lastPeriod, lastNewline);
if (splitPoint > chunkSize * 0.5) {
chunk = chunk.slice(0, splitPoint + 1);
start += splitPoint + 1 - overlap;
} else {
start += chunkSize - overlap;
}
} else {
start = text.length;
}
chunks.push(chunk.trim());
}
return chunks.filter((chunk) => chunk.length > 0);
}
|
3. 文本向量化(Embedding)
这里可以直接调用 OpenRouter 里面提供的 Embedding 模型,比如 thenlper/gte-base
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| async function callOpenRouterEmbeddings(
input: string | string[]
): Promise<any> {
const apiKey = process.env.OPENROUTER_API_KEY
const model = process.env.OPENROUTER_EMBEDDING_MODEL || "thenlper/gte-base"
try {
const response = await fetch("https://openrouter.ai/api/v1/embeddings", {
method: "POST",
headers: {
"Content-Type": "application/json",
Authorization: `Bearer ${apiKey}`,
"HTTP-Referer": "http://localhost:3000",
"X-Title": "RAG Demo",
},
body: JSON.stringify({
model: model,
input: input,
}),
})
const data = await response.json()
return data
} catch (error) {
}
}
|
4. 存储向量数据
可以使用一些向量数据库来存储,比如 Milvus 等,这里为了方便展示,直接存到内存里。
1
2
3
4
5
6
7
8
9
10
11
|
export class VectorStore {
private chunks: DocumentChunk[] = [];
addChunks(chunks: DocumentChunk[]): void {
this.chunks.push(...chunks);
}
}
|
5. 用户提问 - 相似度检测
针对用户的提问,也需要进行向量化,然后进行相似度检测(余弦相似度),找到最相似的几个片段。这里的向量化还是用上面的向量化方式,相似度检测这里直接用 cosine-similarity 库来计算。然后返回相似度最高的几个片段。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
export class VectorStore {
private chunks: DocumentChunk[] = [];
async search(
queryEmbedding: number[],
topK: number = 5
): Promise<DocumentChunk[]> {
const similarities = this.chunks.map((chunk) => ({
chunk,
similarity: cosineSimilarity(queryEmbedding, chunk.embedding),
}));
similarities.sort((a, b) => b.similarity - a.similarity);
return similarities.slice(0, topK).map((item) => item.chunk);
}
}
|
6. 大模型生成
然后就是将检索到的最相关的几个片段,以及用户问题一起放到 Prompt 中,调用大模型来做回答。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
export async function ragQuery(
query: string,
topK: number = 5
): Promise<{
answer: string
sources: DocumentChunk[]
}> {
let context = ""
if (relevantChunks.length > 0) {
context = relevantChunks
.map((chunk, index) => `[文档片段 ${index + 1}]\n${chunk.content}`)
.join("\n\n")
} else {
context = "没有找到相关的文档片段。"
}
const prompt = `请根据以下上下文信息回答用户的问题。如果上下文中没有相关信息,请如实说明。
上下文信息:
${context}
用户问题:${query}
请提供详细且准确的回答:`
const answer = await callLLM(prompt)
return {
answer,
sources: relevantChunks,
}
}
|
五、总结
到此为止,RAG 的简单实现就完成了,当然真正落地还需要很多的优化和改进,比如:
- 向量数据库来持久化存储
- 性能优化
- 向量索引
- 缓存(Redis)
- 流式响应
- 批量生成 embeddings
- 扩展性
- 微服务架构(文档处理服务/向量化服务/检索服务/生成服务)
- 负载均衡/消息队列
- 权限认证
- 监控和可观测性
- 日志
- 指标监控(查询延迟/检索准确率/API调用次数)
- 告警
- 文档处理优化
- 基于语义智能分块,而不是简单按字数或行数切分
- 内容过滤,过滤低质量内容
- 检索策略优化
- 混合检索(向量检索 + 关键词检索)
- 动态 topK
- 用户体验相关
- 指标评估
所以确实真正落地还是有很多需要考量的地方的。





