解析大型语言模型的高效训练与推理之道
《解析大型语言模型的高效训练与推理之道》分享笔记
一、LLM 背景简介
从学术界来看,尤其是 22 年开始,LLM 相关论文的发表频率呈现指数增长,至此大语言模型的应用已经深入了我们生活和工作中。
LLM 模型分类

- Encoder-Decoder: 代表模型 T5,适用于翻译任务
- Encoder-Only: 代表模型 BERT,适用于文本分类
- Decoder-Only: 代表模型 GPT,适用于文本生成类任务
GPT 系列模型,Meta 开源的 LLaMA 模型,结构都是 Decoder-Only 架构
二、LLM 模型核心模块剖析
演示视频:https://www.3blue1brown.com/lessons/gpt
一次 GPT 服务请求,可以等价于 GPT 模型在计算资源上运行多次。
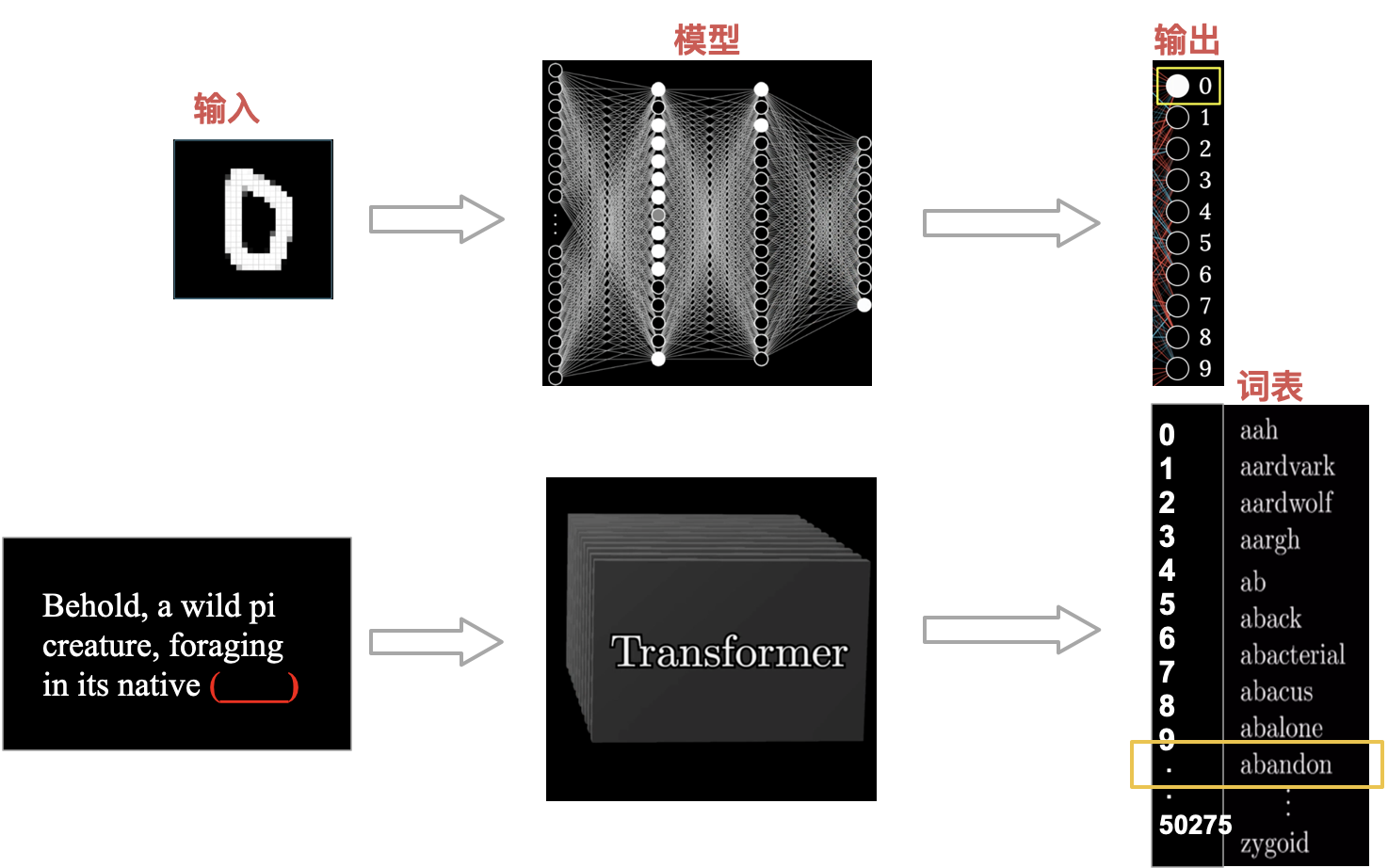
本质:分析预测下一个单词
ChatGPT 本质就是,分析输入句子预测下一个单词,重复运行这个步骤,就具有了回答我们问题的能力,这就是 ChatGPT 回答问题的核心
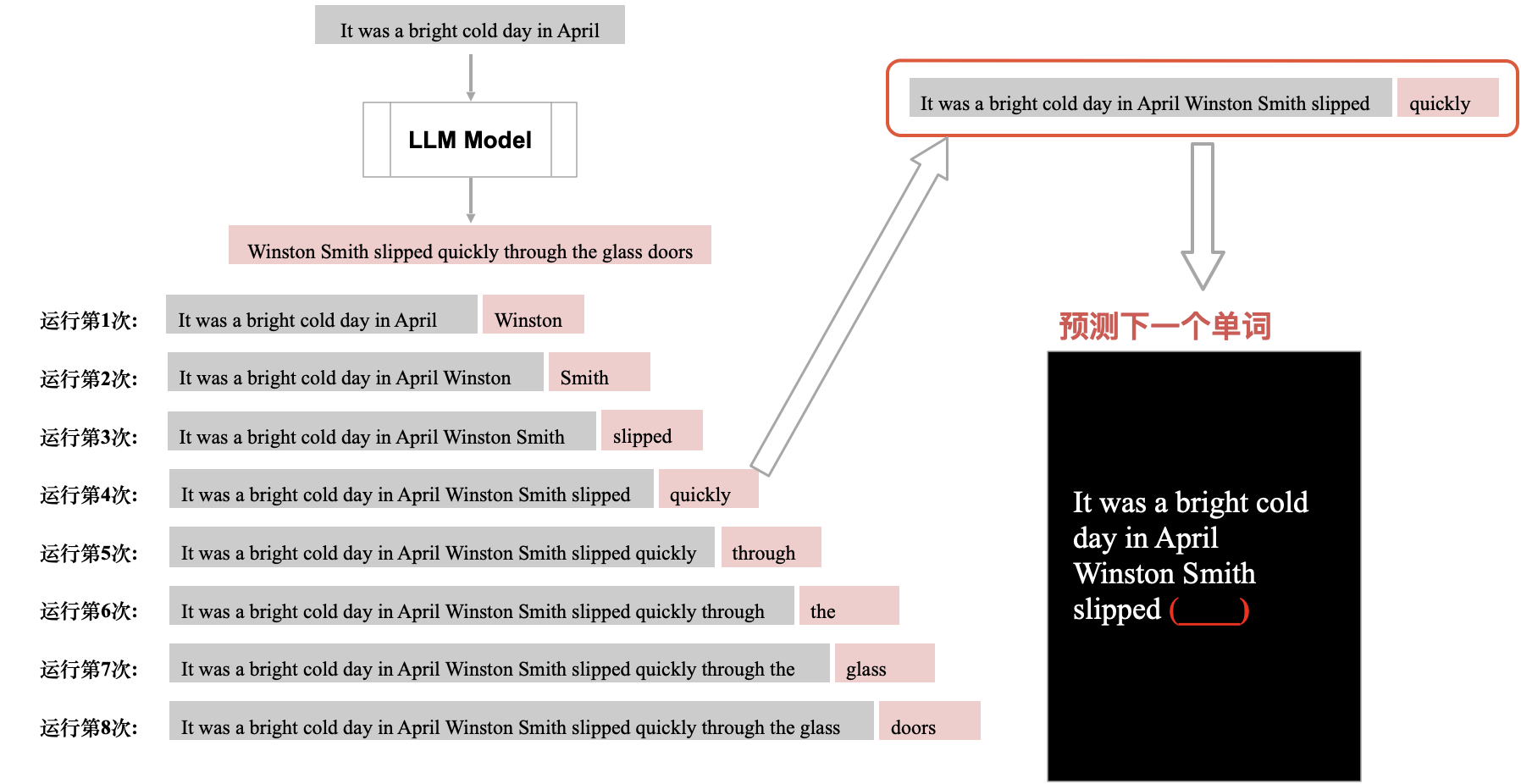
分析输入句子(上文)从词表中选择一个合适单词作为下一个单词

ChatGPT 本质就是,分析输入句子(上文)从词表中选择一个合适单词作为下一个单词,重复这个步骤(每次都会把包含生成的句子重新运算,KValue 缓存可以优化这个部分),实现回答我们的问题,这就是 ChatGPT 回答问题的核心。
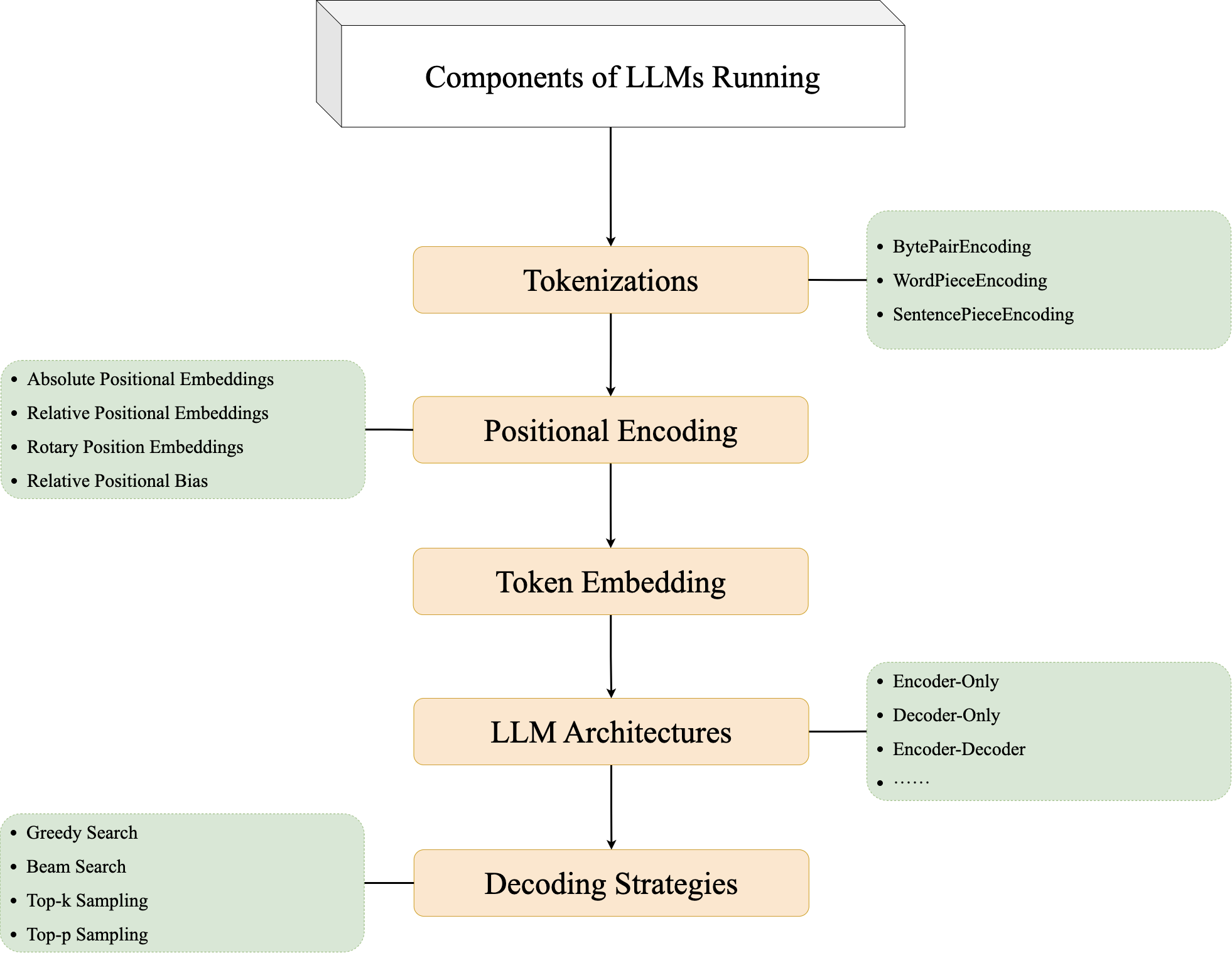
GPT 模型组件
LLM 模型组件解析:
- Tokenizations: 识别单词
- Token Embedding: 学习文字的关系
- Positional Encoding: 学习句子中单词的位置信息
- LLM Architectures: 通过学习句子间的语义关系,预测下一个单词
- Decoding Strategies: 输出合理且丰富多样的回答
Tokenizer
Tokenizer 就是把文字编码为数字,比如 GPT2 词表大小为 50257。可以去 OpenAi 网站查看切分 Tokenizer。
Token Embedding
由向量的关系来表达单词间的语义关系,把我们能理解的单词间的语义关系数字化为模型能理解的语义关系。从 Token(数字)升维转换成空间中的向量。比如 woman,man 与 king,queen 他们之间是有语义关系的,并且在我们的理解上他们之间存在比较接近的语义,最终学到的多维词表他们两者之间的差距也是相似的。
Positional Encoding
将位置信息(可学习的)直接加到单词上,并且以向量的形式来表示位置,和 Text Encoding 异曲同工之妙。
- 函数式的绝对位置编码(Transformer)
- 学习式的绝对位置编码(Bert, ViT,GPT2)
- 函数式的相对位置编码(LLaMa)
- 学习式的相对位置编码(Swin-v2)
LLM Architectures
LLM 模型就是,输入一个句子,然后输出就是模型识别到的结果,他是词表单词中的哪一个。
Decoding Strategies
https://decodingml.substack.com/p/4-key-decoding-strategies-for-llms
https://deci.ai/blog/from-top-k-to-beam-search-llm-decoding-strategies/
解码策略决定了 GPT 模型的结果多样性,使得 ChatGPT 看起来更智能,如图所示每次生成的结果都不太一样,GPT 如何做到结果多样性。
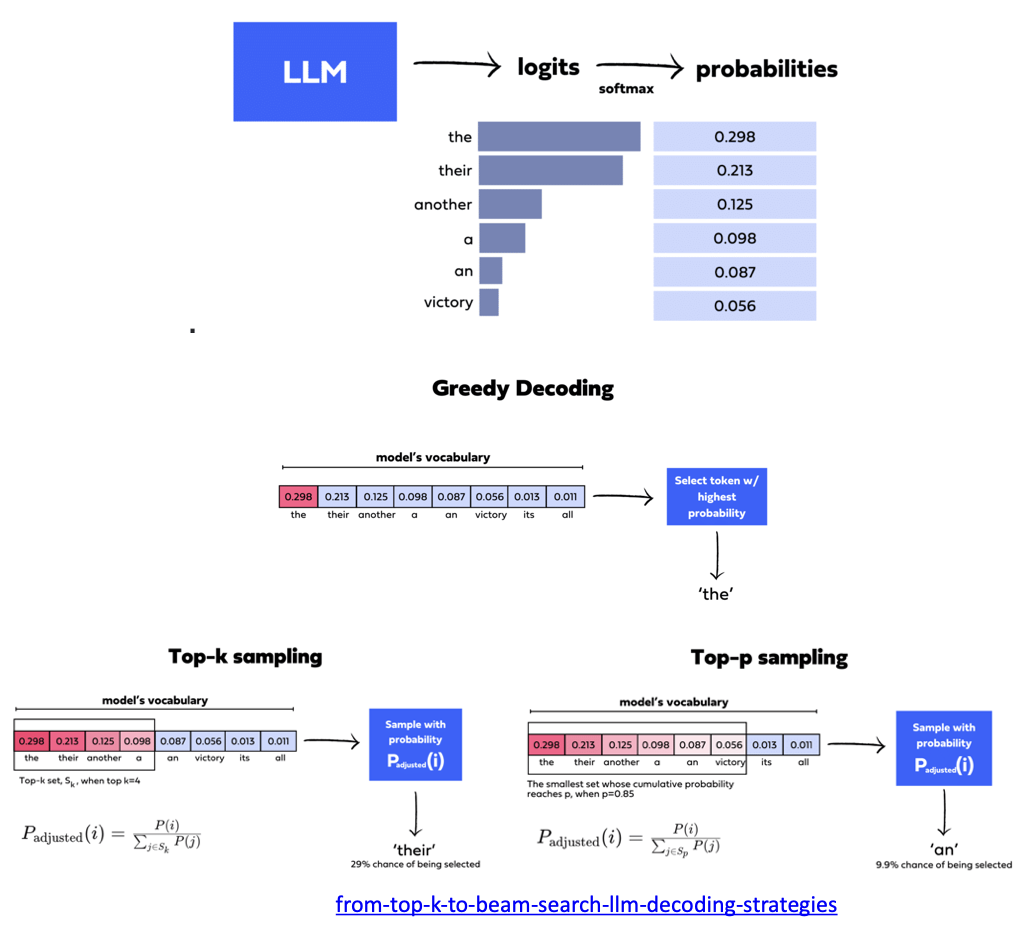
前面我们提到每次都是选择词表对应分数中,概率最大的选项,你会发现每次结果都一样,这个就是 Greedy Decoding 贪心解码。就是选择概率最大的 the,如果是用 Greedy Decoding 那么每次回答都是 the。
Top-K/Top-P 就是排除法把最不可能的几个删除掉,然后里面随机选一个。Top-K/Top-P 这种引入随机性的解码方式,也就是这样我们和 ChatGPT 对话的时候能发现输入同样的问题,他们输出不一样的结果的原因。
三、LLM 计算资源与性能瓶颈分析
CPU 擅长处理少量复杂计算,GPU 擅长处理大量简单线程的并行计算。CPU 画一个笑脸就是一个(相对复杂的操作),需要一个一个点来逐个操作。而 GPU 只需要一次就可以画出一张蒙娜丽莎的图像,GPU 的每一个线程只用画图像中的一个点(这个就是相对简单的操作),但是有大量线程就可以执行并行计算。
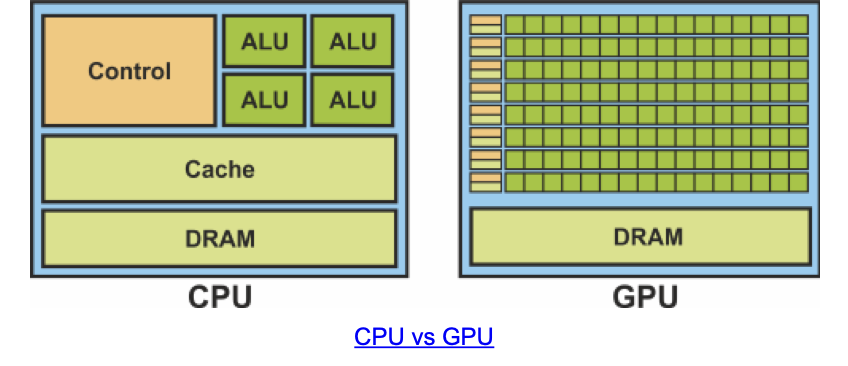
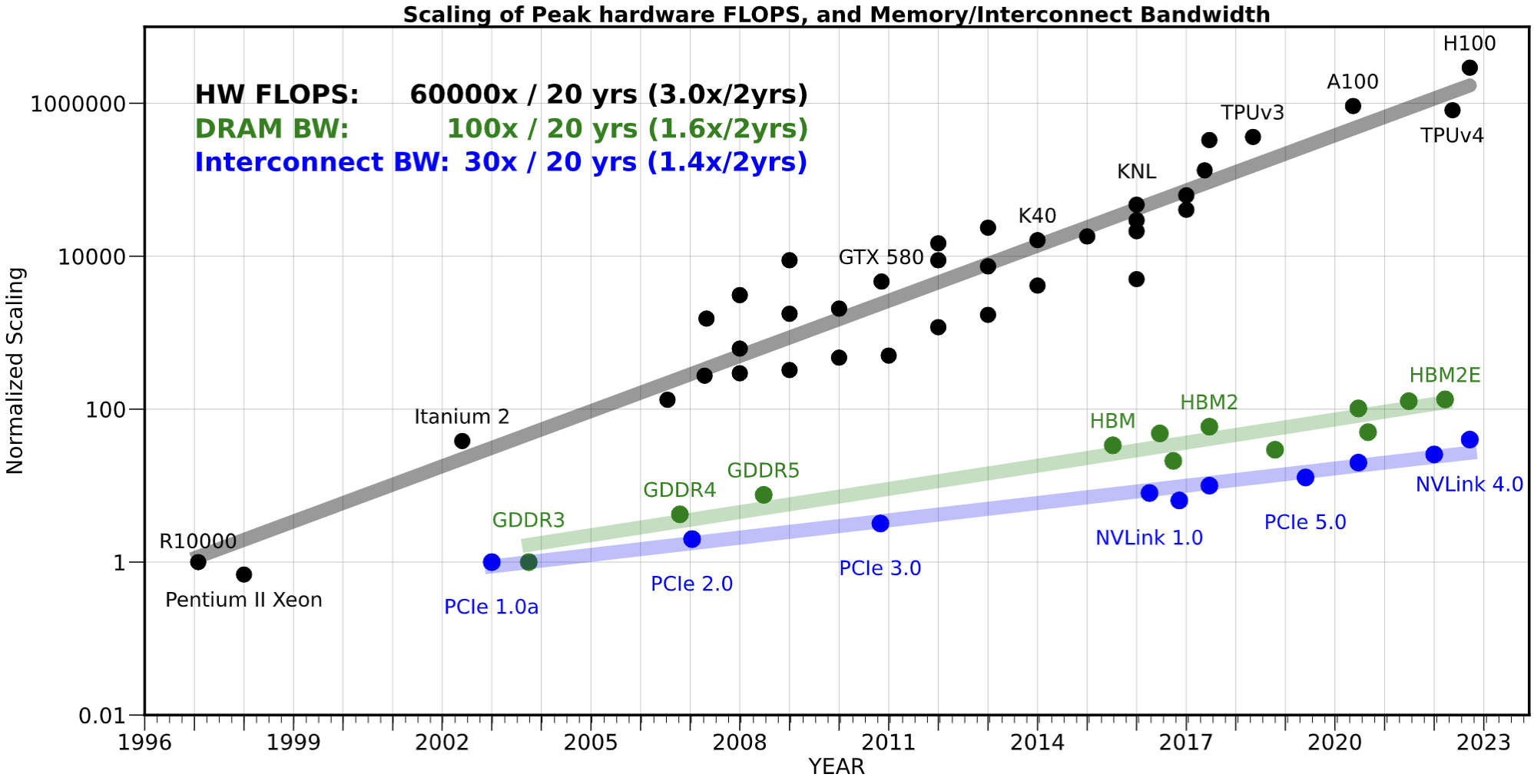
虽然 GPU 并行度非常高,但是 GPU 也都是由存储单元,传输单元,运算单元组成,其性能需要整体考虑。并且随着技术的演进,CPU、GPU 的算力都大幅增加,而内存单元和数据传输速度增长却很慢(内存带宽)。

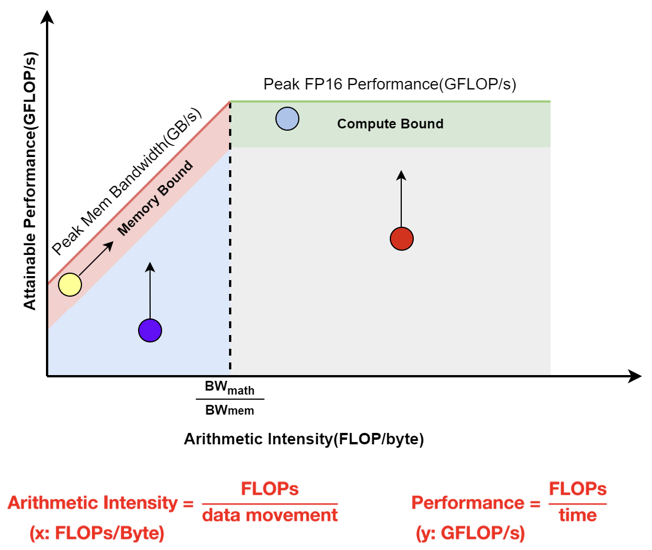
Roofline Model 评估性能瓶颈
- Memory Bound:访存效率较高,需要减少访存
- Compute Bound:计算效率较高,需要减少计算
四、LLM 模型训练优化方法概览
分析师和技术专家估计,训练 GPT-3 等大型语言模型的关键过程可能花费超过 400 万美元(依据算力,换算 Google 云的租赁价格),花费几个月的时间。
模型训练三阶段:Forward,Loss Calculation,Backward
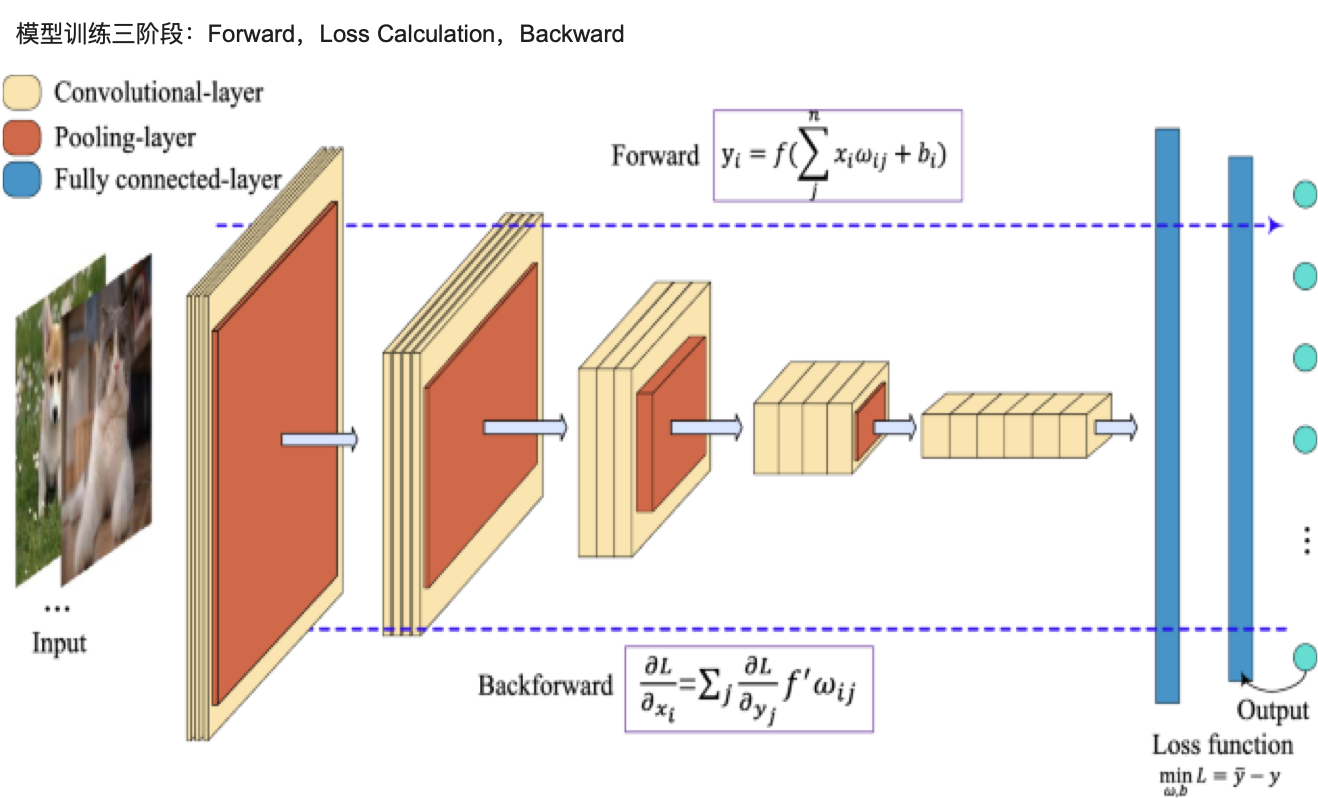
训练三阶段
Forward
Forward 也就是前面咱们所提到的预测下一个 Token 的过程。预测下一个 Token,而我们训练使用的数据是知道下一个 Token 是什么,也就是有正确答案,所以就是依据正确答案计算 Loss。
Loss
如果把 forward 当成做题的过程,其实简单点描述 Loss 就是咱们对答案的过程,只不过稍微比对答案复杂一点。
Backward
对完答案,下一步就是开始修改答案了,这个也就是咱们的 Backward 的过程,所以我们要清楚修改的是什么地方。修改权重。
分布式训练
大模型的变化,由于参数量和计算量激增,比如训练 175B 模型,需要 314ZFLOPS 的计算量,需要几个月时间,而且如果采用单卡的画需要 32 年,并且训练参数也是非常多达到 2TB 的存储规模,而 A100 大卡最大才 80GB,所以需要对模型和数据进行切分然后采用分布式训练的方法进行加速。

微调
由于 LLM 模型参数和计算量都非常大,在对指定任务微调的时候不能重新训练基座模型,就需要使用更高效的方法来微调,当前比较流行的高效微调方法:
- Adapter
- 就是在之前模型结构中插入几层
- LoRA
- 就是在原来权重的部分采用低秩分解,变化为两个更小的权重参数来实现
- Prompt Tuning
- 是在输入前加入特定任务的提示词
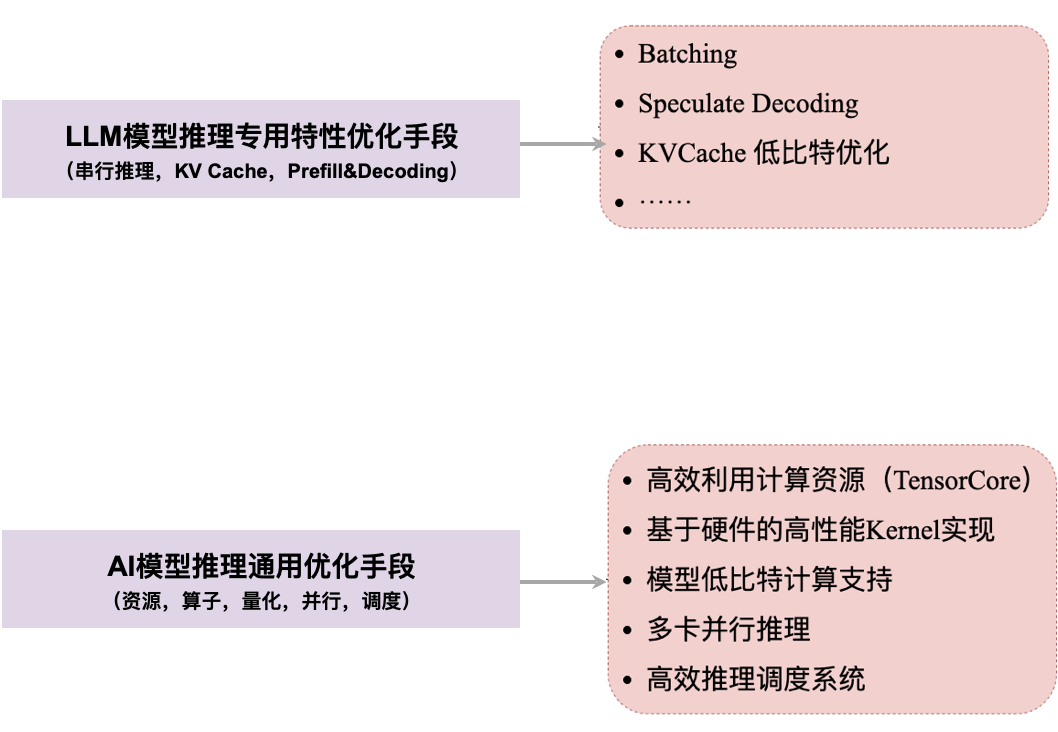
五、LLM 模型推理优化策略解析
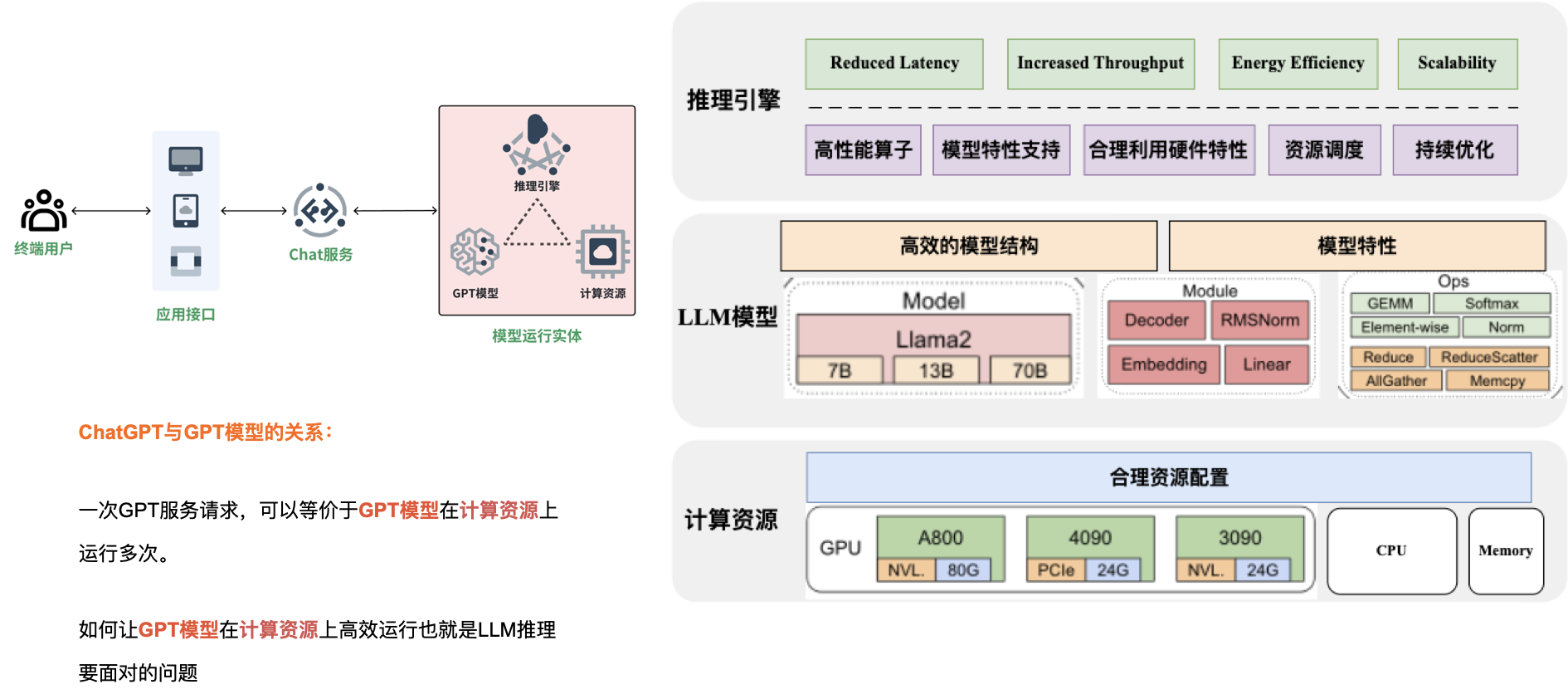
LLM 推理系统关键指标
- Throughput:总的吞吐(output tokens/seconds),对于 LLM Serving 重要,可以提高总的服务能力。越高越好。
- Time to First Token(TTFT):第一个 token 返回的时间,在 stream 输出模式下,对体验影响大,越小用户等待返回第一个 token 时间越小,体验越好,越小越好。
- Times Between Token(TBT):在 decode 阶段,生成每个 token 的时间,影响体验,越小越好。
- Latency:处理完整请求用时,越低越好。
- QPS:每秒处理完成的请求数,越高越好。
特性
- 自回归特性:每次运行结果都会对上一次存在依赖,比如:运行第二次,依赖第一次运行的结果;运行第三次依赖第二次运行的结果,有时序上的依赖,所以预测下一个 Token 的过程,需要逐步进行(串行)。
- KVCache 对显存需求非常大:存在每次输入同样的 Token,存在重复的计算(KV 的 Projection)。我们可以采用空间换时间的思想将需要重复计算的 KV 将其缓存起来。
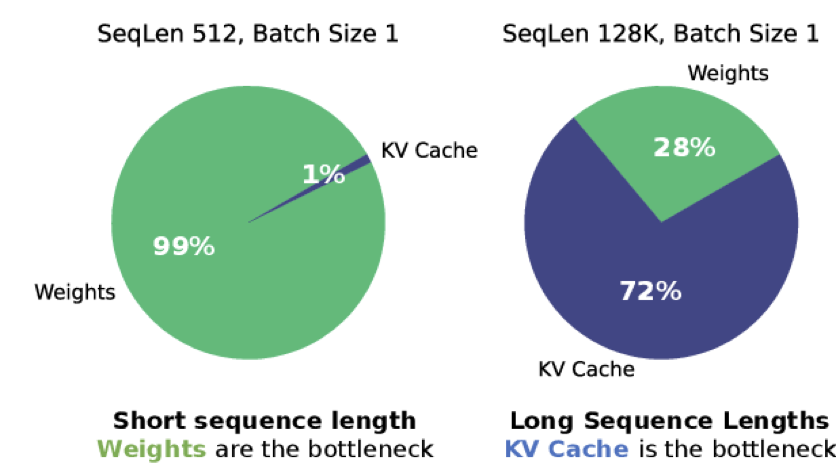
- Prefill 与 Decode 的异质性:因为 KVCache 的存在,我们将推理过程分为了 Prefill 和 Decode 两个阶段 Prefill 和 Decoding 特性介绍(Compute Bound 转换到 Memory Bound),主要耗时都在 decoding 阶段
- 对硬件的性能要求较高:大部分推理场景 GEMM 计算占比最大,需要更高效的 GEMM 运算支持
- 模型参数量/计算量较大
- LLM 高效推理是个复杂的系统问题:LLM 高效推理是个复杂的系统问题,需要考虑,极大的服务访问量,复杂的计算资源调度,巨大的模型参数量,苛刻的计算效率。并且如何构建高效的 LLM 推理系统,也是目前学术界的热点问题。
优化总结