
《全面理解机器智能与生成式 AI 加速的新工业革命》笔记
《智变时代 / 全面理解机器智能与生成式 AI 加速的新工业革命》文章笔记
原文链接:https://mp.weixin.qq.com/s/4LvcfLC6C-dZnS7f_IKw-g
一、模型 - 竞争、泛化与变革的本质
1.1 算力 + 数据
本质:算力 + 数据
第一方面是算力。按照依旧可行的规模理论(Scaling Law),足够多的算力和足够好的数据,就会有足够强大的模型!
所以只要算力足够,Google(Gemini) 和 Meta(Llama) 就能匹敌 OpenAI。而且 Llama 还是开源的,意味着只要有足够多的 GPU(截止 2024.6.14 NVIDIA H100 是最近一代 GPU,价格约 25w 人民币),理论上就能达到 GPT-4 级别的智能。
OpenAI 由于起步早,在收集数据方面处于领先地位。但是随着公开的用于训练的文本耗尽,所以目前越来越多的采用合成数据。但文本之外的图像和视频,需要更直接的接触消费者,才能拿到最新数据。Google 和 Meta 各自的产品线都覆盖了超过三十亿用户,在数据这方面是有优势的。

1.2 模型迭代
RNN & LSTM -> Transformer
Transformer 计算复杂度高,但是并行处理效率高,意味着只要增加算力和数据,就能训练出更好的模型。
如果说内燃机是工业革命范式的动力引擎,现在这个引擎就是 Transformer。模型与算力的组合,就像内燃机和石油的组合那样,成为了通用平台,你提供能源,我就能输出动力。

二、应用 - 智能代理、智能体与组织新形态
2.1 AI 应用现状
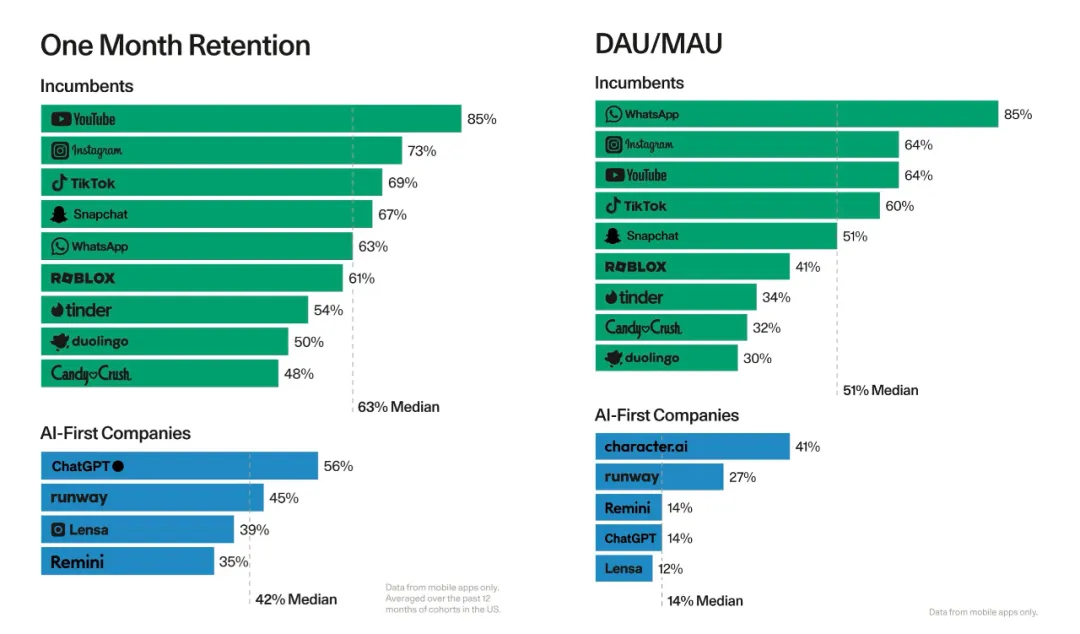
AI 应用还没有爆发,最顶流的 GPT 首月留存率 56%,也不如社交应用的中位数 63%。这意味着用户还没有在这些 AI 原生的产品中找每天使用它们的理由。
那些拥有庞大客户群的上一代的软件或服务公司,他们会有巨大的优势,把基础模型整合到自己的业务流程中,提供新界面,使工作流程更具粘性,输出效果更好。

考虑端到端解决客户需求。这里的核心是,我们如何看待和使用基础模型,而不是简单的封装它们,这些模型就是智能时代操作系统,需要在上面构建原生的应用程序。
类比操作系统
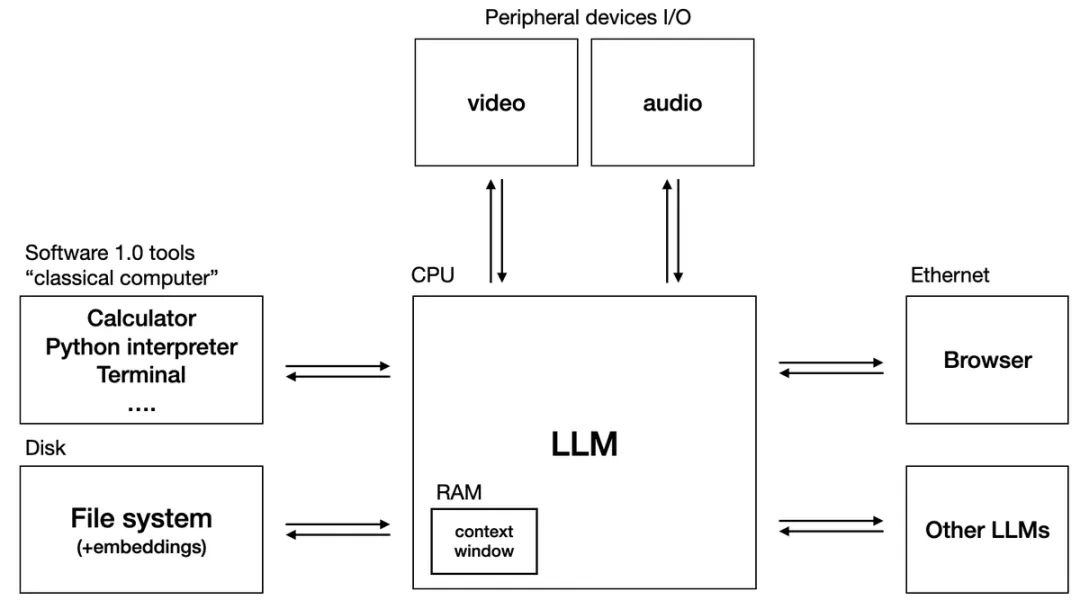
我们可以像操作系统一样使用大语言模型(多模态模型)。不同的地方在于电脑 CPU 接受十六进制汇编指令,LMM 接受自然语言。
LMM 中央处理器的速度就是每秒输出 Tokens 的数量,现在 GPT-4o 大约 50Hz tok/s,规模越小速度越快,当然推理能力也更差。
系统的内存就是 LMM 的上下文窗口(Context Window),一次推理运算最多能接受的 Tokens 数量,现在 Google Gemini 1.5 Pro 实验版已经把这个数字提升到了一千万,一次性输入二十本书和一个小时的电影。但充满挑战也就意味着机会无穷,前沿模型研发团队都力争做到吞吐量、速度还有准确度的最佳平衡。
这一年多以来,大模型应用领域最常用的方法就是 RAG(Retrieval Augmented Generation),这是一种检索增强生成的方法,让模型用大家自定义的数据生成结果,这样就能处理无尽的私有数据,把模型当成高效的推理机器来使用。
技术栈
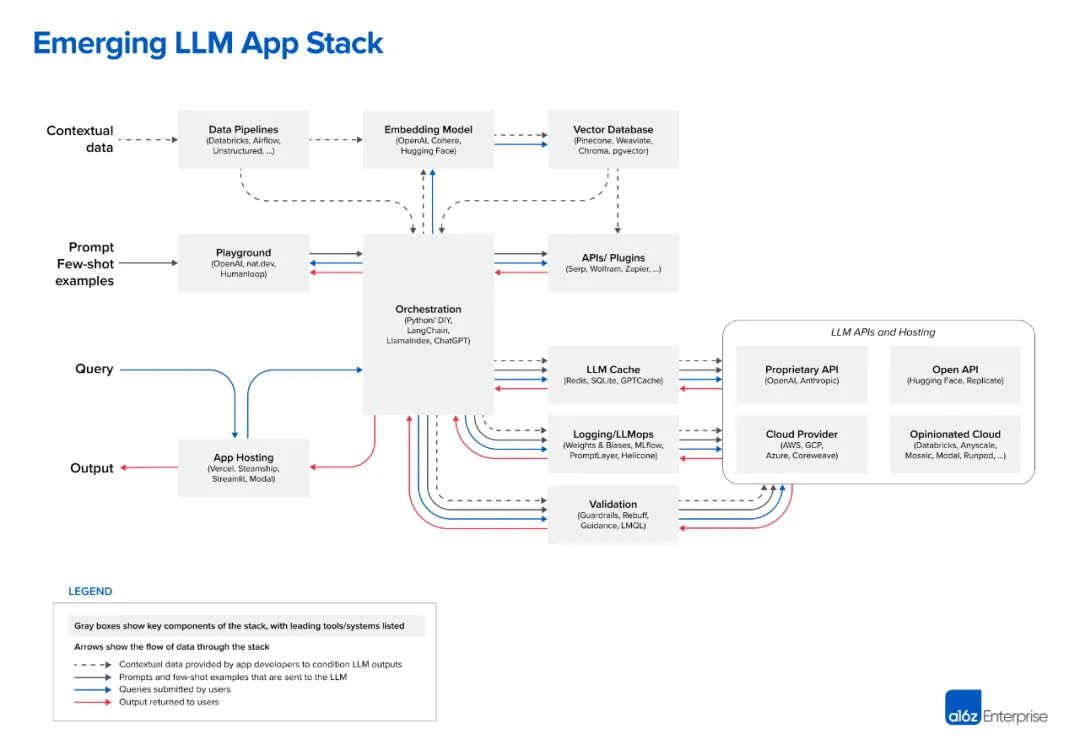
这张图非常好,能帮助一名开发人员理解,在这场 AI 变革时代,我们这样有一些开发基础的人员所能做的一些工作。
1. Data 层
Data 层主要是对数据的处理层,收集数据进行一系列处理之后,降维存入向量数据库中,方便模型使用
1.1 Data Pipelines
- 解释:数据管道是指从原始数据到最终的模型输入数据。它涵盖了数据获取、清洗、预处理、特征工程、数据存储和分发等一系列步骤。
- 数据获取:从各种来源(如数据库、API、文件等)收集原始数据。
- 数据清洗:处理缺失值、异常值、重复数据等问题。
- 数据预处理:对数据进行标准化、归一化、编码等操作。
- 特征工程:提取和选择对模型有用的特征,包括生成新的特征。
- 数据分割:将数据分成训练集、验证集和测试集。
- 数据存储和分发:将处理后的数据存储在合适的存储系统中,并根据需要分发到模型训练或预测的不同节点。
- 代表应用:unstructured
- 将各种数据整合成 LLM 能使用的数据,比如很多企业数据是用 HTML、PDF、CSV、PNG、PPT 等难以使用的格式存在,因此这一部分是用来转换复杂数据的部分
1.2 Embedding models
- 解释:通过将复杂的高维数据表示为低维向量,使得在机器学习任务中处理和分析这些数据变得更加高效和准确。
- 降维:将高维数据映射到低维空间,减少计算复杂度。
- 表示学习:学习到的数据表示能够捕捉数据的语义和结构信息。
- 相似度计算:通过计算向量之间的距离或相似度来衡量数据点之间的关系。
- 与上面的不同是,Data Pipelines 输出的是经过处理和清洗的数据。Embedding models 输出的是低维向量表示。所以向量数据库会在 AI 中应用广泛。
1.3 Vector Database
- 解释:即向量数据库,用于存储上一步 Embedding models 转换成的相对低维的向量数据。
- 比如:单词 “king” 的向量表示可能是:[0.2, 0.5, 0.1, -0.3, …]
2. Prompt Few-shot examples
所以这部分,个人理解,即对外用户暴露的部分。也就是和用户直接交互的部分。
2.1 Playground
- 解释:Playground 是一个交互式环境,通常用于实验和测试不同的提示(prompts)和模型配置。在 Playground 中,用户可以方便地输入各种提示并观察模型的输出,从而找到最佳的提示策略。
- 交互测试:实时输入和修改提示,观察模型的反应。
- 调试和优化:快速尝试不同的提示和参数,找到最佳配置。
- 学习和探索:了解模型如何响应不同类型的输入,掌握提示工程的技巧。
2.2 Orchestration
- 解释:指的是管理和协调多个模型或组件,以实现更复杂和高级的任务。即逻辑编排组合工作流。
2.3 APIs/Plugin
- 解释:对于开发很容易理解,通过 API 和 Plugin,模型对外暴露服务和数据源。或者扩展等等。
3. Query & Output
这部分图上画了一个 App Hosting,看到 Vercel 之后就很容易理解了。即服务托管这部分,快速的进行部署等。
4. LLM 基础建设
4.1 LLM Cache
- 解释:看到 Redis 之后就很容易理解了,即为了提高模型推理速度和效率的缓存系统。
4.2 Logging/LLMops
- 解释:这部分对于开发也很容易理解,就是服务治理那一部分,比如性能监控,错误日志记录,操作日志等等。
4.3 Validation
- 解释:个人理解这部分和单元测试很像,保证模型训练和部署过程中评估模型性能。
5. LLMAPis and Hosting
这部分基本就是对外提供的和对内提供的 API,以及云服务相关,和上面的部分,个人理解有重合之处。
三、智变 - 廉价诱导需求、从中心到边缘算力、新工业革命
现代经济学中有一个简单的定义:当商品、服务或资源的供应或容量增加导致其消费增加时,就会发生诱导需求(Induced demand)。经济学家 George Gilder 在《Knowledge and Power》中最核心的观点就是经济增长的主要动力就是企业家的创新,产生供给端需求,俗称创造不存在的市场。
智能的供应取决于两方面的成本:训练与推理,除非若干年后我们有了全新的训练推理一体的自进化模型架构。OpenAI 的推理成本似乎在以每年约 86% 的速度下降,比训练成本降的更快,最新模型 GPT-4o 和去年同等智能水平的 GPT-4 相比,速度提升了五倍,价格下降了接近十倍,这只是在一年之内。
行业周期切换
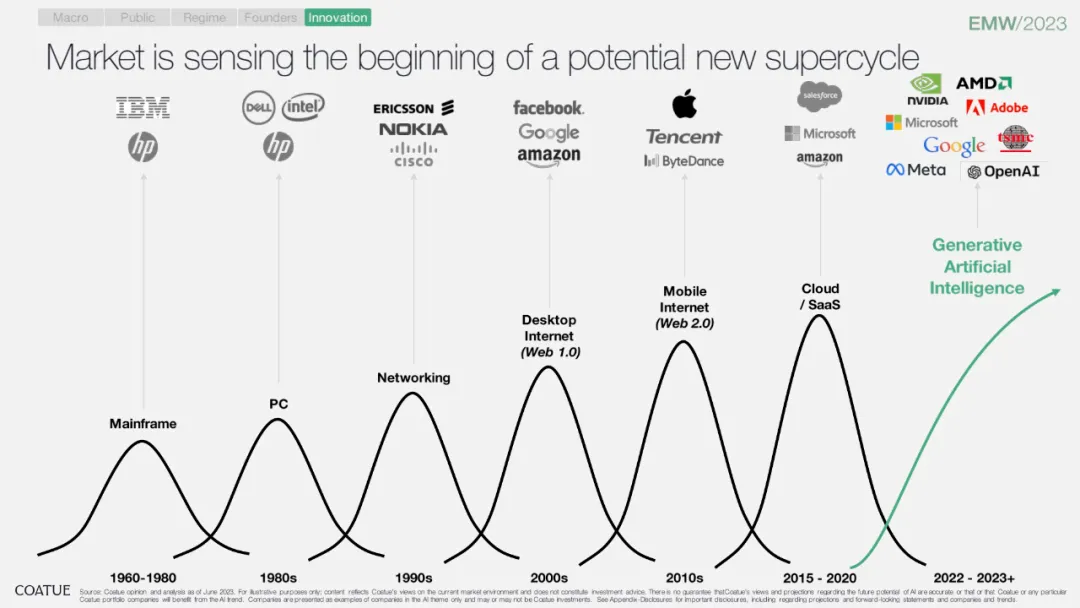
虽然在 2010s 的描述并不是很符合个人认知。Mobile Internet 个人理解是和 Cloud / Saas 存在同一时代的,而且也并没有被 Cloud / Saas 替代。
现在正处于 AI 基础设施第二轮的升级浪潮之中:
- AI 服务器的占比:9%
- AI 在整个半导体行业的收入占比:10%
- AI 数据中心电力消耗的占比(美国):2+ %
- AI 云计算收入的占比(Amazon & Microsoft):~ 3%
从百分之九到百分之九十,AI 数据中心的升级才刚刚开始。因此,这次智能革命,会让芯片和数据中心业务最先受益,从 Nvidia 的股价就能看出;另外业务用量的提升,AI 云计算收入,其实主要是模型托管的收入,将成为云计算公司的主要收入。
能源
这里特别提到了能源, Coatue 预估按照现在的电力基础设施,到 2030 年全美国的电力供应将没法支撑 2500 万块数据中心 GPUs 的消耗,现在才 300 万块 GPUs;电力的产量提升并不如算力提升那么容易,Mark Zuckerberg 在最近一次与 Dwarkesh 的播客对谈中,特别吐槽了这一点,电力供应将成为 AI 发展的最大瓶颈!
四、演化 - 模型如何理解和进化、自主目标与自动化的 AGI
这一章更多的是对 AI 的一些预测
五、选择 - 职业变迁、自我提升与科技恒大
杰文斯悖论(Jevons Paradox),在劳动力市场上也一样,效率的提高会导致工作岗位的短期减少,但长期的需求激增会创造更多的工作岗位。Slow Venture 的合伙人 Sam Lessin 做过一个有趣的类比:“每个人都认为 AI 将会彻底改变法律行业 。。这种想法是错误的 ;AI 将使生成和处理冗长的合同变得易如反掌,导致诉讼量激增十倍,法律业务将蓬勃发展,成为 GDP 的主要组成部分。。就像之前的金融行业一样!”
自动化技术提高了以前没法自动化任务的生产力,从而增加了对这些任务的需求。例如,白领在会计、销售、物流、交易和一些管理职位上,部分任务被专门软件和 AI 所取代,但这些技术也提高了生产力,从而增加了对这些任务的需求;但在制造业中却不同,自动化的加速导致了劳动需求的停滞,但新任务的创造速度在减慢,从而对劳动需求产生了负面影响。研究委婉的表达了制造业在全部制动化之后,就没人类工作者什么事儿了。
法律、医疗、工程、科学和教育这些处于“知识越多,工作也越多”的领域。将会是需求激增的受益行业,另外娱乐还有餐饮服务业一直处于增长趋势,在各行各业都自动化之后,唯有吃喝玩乐得人们亲自来,所以这将是智能富足社会的常青行业。






