从零搭建 Node Faas(二)运行时设计 运行时可以说是搭建 Faas 过程中最核心的部分,因为这决定了整个 Faas 的实现方式。
所以第一篇文章就从运行时开始整理。
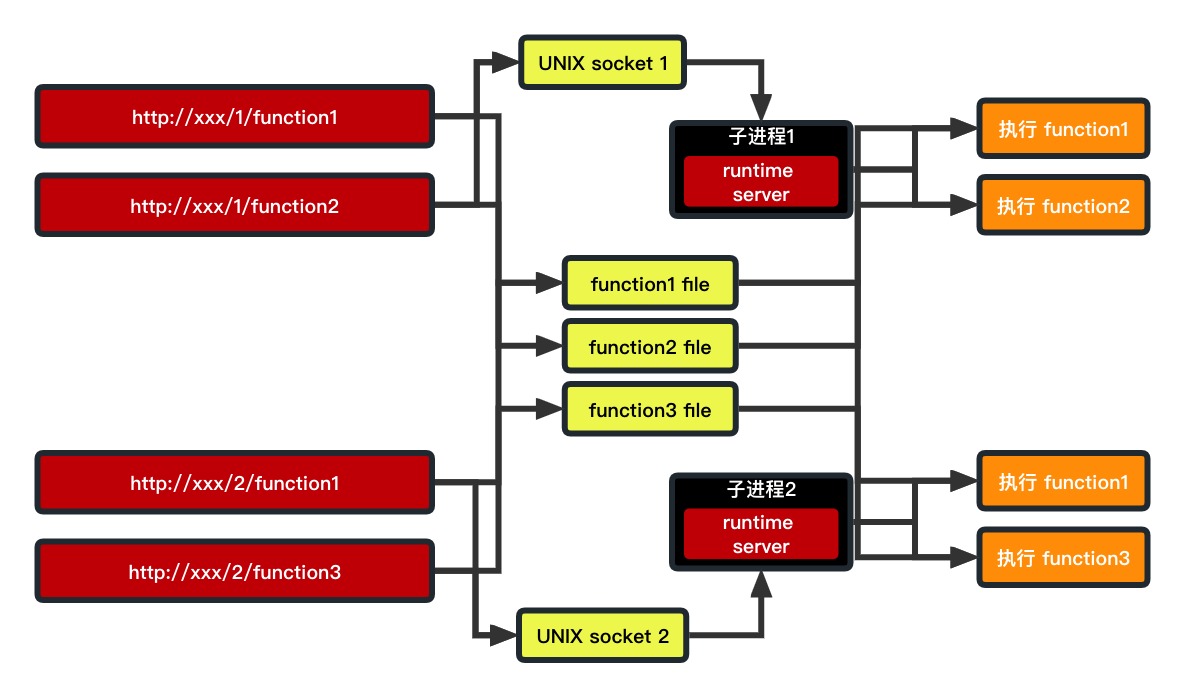
一、整体流程
这是第一篇文章中出现过的图,当一个请求进入主进程之后,会被代理到子进程,这是第一个关键的技术点。
然后子进程中在沙箱中执行代码,这是第二个关键的技术点。
所以文章也会从这两个方面去进行梳理。
二、应用进程
图中有两个应用 1 和 2,然后应用 1 有两个 function,分别是 function1 和 function2。应用 2 有两个 function 分别是 function1 和 function3。
然后应用 1 的请求进来之后,会通过 UNIX socket 被代理到子进程 1,应用 2 同理会被代理到子进程 2。
这个过程的简单版本你可以在 faas-demo 中看到。
1. 主进程 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 import { createProxyMiddleware } from "http-proxy-middleware" const app = express ()const port = 3000 app.use ( "/:appId/:functionName" , async (req, res, next) => { next () }, createProxyMiddleware ({ router : async (req) => { const { appId } = req.params const processId = await ensureApplication (appId) return { socketPath : path.resolve (getProcessDir (processId), "runtime.sock" ), } as any }, }) )
这是一段主进程的简化版本代码。核心部分就是 createProxyMiddleware 这一段,里面的 socketPath 就是将请求通过 UNIX socket 代理到子进程的部分。
2. 进程调度 上面主进程的代码中有一行。
1 const processId = await ensureApplication (appId)
这一行就是拿到当前应用所对应的进程。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 const idleProcesses : string [] = []export async function getIdleProcess ( if (idleProcesses.length ) { const id = idleProcesses.pop ()! logger.info (`use pre-created idle process id=${id} ` ) return id } const processId = generateProcessId () logger.info (`no idle process, create a new one id=${processId} ` ) await createProcess (processId) createIdleProcess () return processId }
这里有一个闲置队列进程 idleProcesses。没有闲置进程的情况下,会新创建闲置进程。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 export async function createProcess (processId : string const child = exec (`node ${path.resolve(__dirname, "start.js" )} ` , { cwd : processDir, env : { ...process.env , FAAS_PROCESS_ID : processId, }, }) await waitOn ({ resources : [`http://unix:${processDir} /runtime.sock:/__health_check` ], timeout : 5000 , }) const interval = setInterval (async () => { const alive = await checkProcess (processId, child) if (!alive) { clearInterval (interval) } }, 10000 ) }
到这里,进程调度基本就结束了。当然这里并没有采用复杂的调度策略。为了让整个流程更加清晰,简化了这个过程。
3. 子进程 1 2 3 4 5 6 7 8 9 10 11 12 export async function startServer ( const server = createServer () await fs.promises .writeFile ("runtime.pid" , process.pid .toString ()) await fs.promises .rm ("runtime.sock" , { force : true }) server.listen ("runtime.sock" ) }
生成的 runtime.sock 就能通过 UNIX socket 来把请求从主进程代理到子进程了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 export function createServer (ReturnType <typeof express> { const app = express () app.get ("/__health_check" , (req, res ) => { res.status (200 ).send ("ok" ) }) app.all ("/:appId/:functionName" , handler) async function handler (req : express.Request , res : express.Response } return app }
然后子进程会有一个 /__health_check 路径,来让主进程定期轮训检查是否失活。
到这里,主进程代理到子进程的整个过程都已经清楚明了了。
4. 主进程子进程通信 这里还有一个小问题,主进程拿到的 function code,怎么传递给子进程。Node 进程通信有如下几种方式:
IPC 通过 child_process.send() 和 process.on('message')
文件系统
Sockets
之前的进程代理是通过 Socket 来实现的。function code 文件内容比较大,因此通过文件系统来实现主进程和子进程的通信。
可以按照文件的 hash 来命名,将 function 内容存成文件,然后在请求过来的时候,将 hash 放在请求头里面,携带传递给子进程。
然后子进程去找对应的 hash 文件即可。
5. 子进程执行目录结构
.workspace
process-0
process-1
process-2
三、沙箱执行 我们知道 NodeJS 有内置的 vm 模块,用于在当前 Node 进程中创建独立的 JavaScript 上下文,用以执行代码片段。
但是我们希望限制掉一些 Node 模块的引用,比如 fs, process 等等有可能会出现不安全问题的模块。基于这个原因原则了 vm2 这个第三方模块。用于配置更多的安全性控制。
1 2 3 4 5 6 7 8 9 10 11 12 13 async function handler (req : express.Request , res : express.Response const sandbox = createSandbox (req, res) const vm = createVM (sandbox, root) try { await vm.run (wrapCode (code)) } catch (e : any ) { logger.stack (e) res.status (500 ).send ({ message : e.message }) } }
1. 创建上下文 这里的核心执行代码如上,创建上下文 sandbox 之后,创建一个 vm 沙箱,然后在沙箱中去执行 function 代码。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 export function createSandbox ( req : Request , res : Response __context__ : Context __result__ : { status : number data : any } __callback__ : () => void __faas_tables__ : Array <{ displayName : string ; name : string }> console : Console Buffer : typeof Buffer URL : typeof URL process : { env : Record <string , string | undefined > } } { const sandbox = { __context__ : context, __result__ : result, __callback__ : () => { if (isStream.readable (result.data )) { res.status (result.status ) result.data .pipe (res) return } res.status (result.status ).send (result.data ).end () }, __initialize_global__ : initializeGlobal, __faas_tables__ : JSON .parse (process.env .FAAS_TABLE || "[]" ), console , fetch, Buffer , URL , process : { env : { }, }, } return sandbox }
沙箱上下文如上,其中定义了一些常用方法。比如设置返回 data,返回 status,重写 console,以及一些 process.env 定义等等,你也可以根据需要自行定制。
2. 创建 VM 执行环境 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 const blacklist = [ "child_process" , "cluster" , "fs" , "process" , "worker_threads" , "v8" , "vm" , ] export function createVM (_sandbox : any , root : string | string [] return new NodeVM ({ sandbox, require : { external : true , root, resolve (moduleName ) { return require .resolve (moduleName, { paths : roots }) }, builtin : builtin.filter ((x ) => !blacklist.includes (x)), }, env : sandboxProcess.env , }) }
最终的 VM 里面将一些内置模块设置成了黑名单,禁止引入。
沙箱执行到这里基本就实现了。
3. 依赖管理 当然,这里还有一个小问题。那就是函数的依赖管理是怎么做的?
目前并没有提供自定义依赖的功能。目前运行时会提供一些常见的第三方依赖,能保证大部分逻辑都能开发实现,如果有特别需要的第三方依赖,也可以联系开发者按需添加。
所以在部署服务的时候,会把需要的第三方依赖包在指定路径下全部安装好,然后子进程启动在指定的 WORKSPACE 下即可。
四、运行时总结 可以看到这个 faas 运行时的实现功能是比较简易的,核心就是每一个应用启动一个独立子进程,保证应用之间的隔离。然后代码在沙箱中执行,做一些安全策略的限制。
一些展望
动态分配每一个应用的 app 的实例个数
因为每个应用的需要的资源不同,如何更加合理的管控资源分配?
进程的 内存/QPS 限制措施
目前进程启动后,长时间没有触发,会定期清理。但是没有额外的限制措施,如果一个进程使用的使用的内存过大,是否会对其他进程造成影响?
k8s 来做弹性扩缩容怎么做更加合适?